Statistics
Satistics - Introduction
https://numpy.org/doc/stable/reference/routines.statistics.html
import numpy as np
import pandas as pd
1. Simple Statistical Exploration
A = np.random.rand(10,10)
A
array([[7.16622070e-01, 8.67937006e-01, 8.56064808e-01, 8.57568350e-01,
3.67796230e-01, 2.14346363e-01, 6.31599734e-01, 3.57119296e-01,
4.35844862e-01, 2.35483572e-01],
[7.22209004e-01, 9.63310994e-01, 8.16973750e-01, 8.06853501e-01,
6.89970795e-01, 5.83418094e-01, 2.65411361e-02, 7.51624520e-01,
9.59391711e-02, 4.15581862e-01],
[8.57467652e-01, 9.63049501e-01, 7.90326873e-01, 7.95018533e-01,
7.18152201e-01, 4.38823904e-01, 6.45775017e-01, 7.60717860e-01,
9.24224445e-01, 3.13183949e-01],
[3.83836565e-01, 8.56498268e-01, 5.93058237e-01, 2.46908006e-01,
3.10960918e-01, 6.21511447e-01, 2.91997569e-01, 8.13963097e-01,
2.01951380e-01, 5.79517413e-01],
[8.41978469e-02, 3.81861596e-01, 1.24320969e-01, 1.92482070e-01,
4.70194470e-01, 9.69335675e-01, 2.07682914e-01, 8.99462218e-01,
3.56681685e-01, 2.10451446e-01],
[2.50727875e-01, 4.45871405e-01, 4.75621851e-01, 1.76392569e-01,
4.44494388e-01, 1.97214743e-01, 2.23416686e-01, 9.79333246e-01,
2.13115739e-01, 3.26530393e-01],
[6.18496895e-01, 8.46193255e-01, 9.20304738e-01, 4.49655661e-01,
6.66495695e-01, 7.23878345e-01, 4.71483753e-01, 3.35079701e-01,
2.80457713e-01, 4.17035078e-01],
[3.74931699e-01, 1.64469071e-02, 8.24518210e-01, 4.40508140e-01,
3.04546586e-01, 9.61964988e-01, 9.13281778e-01, 1.08067818e-01,
3.52596222e-01, 9.71936660e-01],
[6.24254898e-01, 6.83181203e-01, 7.55043126e-01, 5.46638933e-01,
1.40146074e-01, 8.45252325e-02, 2.54143985e-01, 4.85118512e-04,
8.08711713e-01, 9.33249065e-01],
[4.10573251e-01, 6.30441143e-01, 6.04971277e-01, 4.07647377e-01,
8.25351233e-01, 5.19909474e-01, 9.76184695e-02, 8.11742544e-01,
6.04160360e-01, 4.48347194e-01]])
A.shape
(10, 10)
A.max()
0.9793332463866128
A.min()
0.00048511851159238617
A.mean()
0.523381592476641
np.median(A)
0.47355280212201306
A.std()
0.2772531462004282
np.cov(A)
array([[ 0.06873698, 0.03278827, 0.03668793, -0.00331421, -0.05083651,
-0.00850994, 0.02390898, -0.02626347, 0.03131505, -0.01397033],
[ 0.03278827, 0.09816338, 0.01792033, 0.04059124, 0.01004886,
0.02993195, 0.03987967, -0.05153719, -0.00568755, 0.03430207],
[ 0.03668793, 0.01792033, 0.04244191, -0.00450095, -0.0155604 ,
0.00718968, 0.00519803, -0.05720041, 0.00948249, 0.01091863],
[-0.00331421, 0.04059124, -0.00450095, 0.05553323, 0.03406878,
0.03667575, 0.01972246, -0.01604353, -0.00940025, 0.02010751],
[-0.05083651, 0.01004886, -0.0155604 , 0.03406878, 0.09681987,
0.03356765, -0.00601017, -0.01500941, -0.0759788 , 0.0324855 ],
[-0.00850994, 0.02993195, 0.00718968, 0.03667575, 0.03356765,
0.0581328 , -0.00229493, -0.04089154, -0.03034172, 0.03377649],
[ 0.02390898, 0.03987967, 0.00519803, 0.01972246, -0.00601017,
-0.00229493, 0.04676247, 0.00605692, 0.00312176, 0.00634826],
[-0.02626347, -0.05153719, -0.05720041, -0.01604353, -0.01500941,
-0.04089154, 0.00605692, 0.13017446, 0.01244017, -0.04495907],
[ 0.03131505, -0.00568755, 0.00948249, -0.00940025, -0.0759788 ,
-0.03034172, 0.00312176, 0.01244017, 0.11204687, -0.01455545],
[-0.01397033, 0.03430207, 0.01091863, 0.02010751, 0.0324855 ,
0.03377649, 0.00634826, -0.04495907, -0.01455545, 0.04560073]])
Mean and std of row
np.mean(A,axis =0)
array([0.50433178, 0.66547913, 0.67612038, 0.49196731, 0.49381086,
0.53149283, 0.3763541 , 0.58175954, 0.42736833, 0.48513166])
np.std(A,axis =0)
array([0.22924647, 0.28962689, 0.22578381, 0.24259586, 0.21017855,
0.2908006 , 0.26627669, 0.33170298, 0.25736132, 0.25495454])
Mean and std of col
np.mean(A,axis =1)
array([0.55403823, 0.58724228, 0.72067399, 0.49002029, 0.38966709,
0.37327189, 0.57290808, 0.5268799 , 0.48303793, 0.53607623])
np.std(A,axis = 1)
array([0.2487233 , 0.29723231, 0.19544236, 0.22356186, 0.29519126,
0.2287346 , 0.20514927, 0.34228207, 0.31755658, 0.20258494])
2. Feature Scaling:
-
- Mini-max scalar
A = (100*np.random.rand(10,10)).astype(int)
A
array([[59, 39, 55, 69, 55, 10, 89, 79, 71, 77],
[36, 72, 69, 36, 38, 43, 21, 53, 65, 18],
[29, 78, 85, 77, 11, 85, 73, 83, 47, 82],
[17, 70, 94, 48, 10, 68, 92, 96, 12, 56],
[ 5, 54, 30, 57, 86, 49, 10, 22, 17, 73],
[46, 36, 63, 60, 64, 95, 76, 64, 13, 93],
[79, 98, 56, 67, 38, 21, 16, 67, 15, 13],
[45, 11, 90, 26, 64, 25, 10, 33, 97, 36],
[86, 88, 68, 24, 40, 20, 17, 59, 83, 74],
[67, 76, 64, 47, 73, 82, 77, 67, 15, 49]])
A_mm = (A - A.min())/(A.max()-A.min())
A_mm
array([[0.58064516, 0.3655914 , 0.53763441, 0.68817204, 0.53763441,
0.05376344, 0.90322581, 0.79569892, 0.70967742, 0.77419355],
[0.33333333, 0.72043011, 0.68817204, 0.33333333, 0.35483871,
0.40860215, 0.17204301, 0.51612903, 0.64516129, 0.13978495],
[0.25806452, 0.78494624, 0.86021505, 0.77419355, 0.06451613,
0.86021505, 0.7311828 , 0.83870968, 0.4516129 , 0.82795699],
[0.12903226, 0.69892473, 0.95698925, 0.46236559, 0.05376344,
0.67741935, 0.93548387, 0.97849462, 0.07526882, 0.5483871 ],
[0. , 0.52688172, 0.2688172 , 0.55913978, 0.87096774,
0.47311828, 0.05376344, 0.1827957 , 0.12903226, 0.7311828 ],
[0.44086022, 0.33333333, 0.62365591, 0.59139785, 0.6344086 ,
0.96774194, 0.76344086, 0.6344086 , 0.08602151, 0.94623656],
[0.79569892, 1. , 0.5483871 , 0.66666667, 0.35483871,
0.17204301, 0.11827957, 0.66666667, 0.10752688, 0.08602151],
[0.43010753, 0.06451613, 0.91397849, 0.22580645, 0.6344086 ,
0.21505376, 0.05376344, 0.30107527, 0.98924731, 0.33333333],
[0.87096774, 0.89247312, 0.67741935, 0.20430108, 0.37634409,
0.16129032, 0.12903226, 0.58064516, 0.83870968, 0.74193548],
[0.66666667, 0.76344086, 0.6344086 , 0.4516129 , 0.7311828 ,
0.82795699, 0.77419355, 0.66666667, 0.10752688, 0.47311828]])
from sklearn import preprocessing
A_scaled = preprocessing.MinMaxScaler().fit(A).transform(A)
A_scaled
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\utils\validation.py:595: DataConversionWarning: Data with input dtype int32 was converted to float64 by MinMaxScaler.
warnings.warn(msg, DataConversionWarning)
array([[0.66666667, 0.32183908, 0.390625 , 0.8490566 , 0.59210526,
0. , 0.96341463, 0.77027027, 0.69411765, 0.8 ],
[0.38271605, 0.70114943, 0.609375 , 0.22641509, 0.36842105,
0.38823529, 0.13414634, 0.41891892, 0.62352941, 0.0625 ],
[0.2962963 , 0.77011494, 0.859375 , 1. , 0.01315789,
0.88235294, 0.76829268, 0.82432432, 0.41176471, 0.8625 ],
[0.14814815, 0.67816092, 1. , 0.45283019, 0. ,
0.68235294, 1. , 1. , 0. , 0.5375 ],
[0. , 0.49425287, 0. , 0.62264151, 1. ,
0.45882353, 0. , 0. , 0.05882353, 0.75 ],
[0.50617284, 0.28735632, 0.515625 , 0.67924528, 0.71052632,
1. , 0.80487805, 0.56756757, 0.01176471, 1. ],
[0.91358025, 1. , 0.40625 , 0.81132075, 0.36842105,
0.12941176, 0.07317073, 0.60810811, 0.03529412, 0. ],
[0.49382716, 0. , 0.9375 , 0.03773585, 0.71052632,
0.17647059, 0. , 0.14864865, 1. , 0.2875 ],
[1. , 0.88505747, 0.59375 , 0. , 0.39473684,
0.11764706, 0.08536585, 0.5 , 0.83529412, 0.7625 ],
[0.7654321 , 0.74712644, 0.53125 , 0.43396226, 0.82894737,
0.84705882, 0.81707317, 0.60810811, 0.03529412, 0.45 ]])
-
- Standard Scalar
A = (100*np.random.rand(10,10)).astype(int)
A
array([[17, 26, 40, 45, 98, 42, 77, 67, 1, 98],
[ 8, 52, 68, 2, 6, 89, 76, 44, 2, 4],
[30, 57, 9, 48, 57, 26, 71, 42, 49, 0],
[13, 18, 65, 81, 36, 2, 25, 7, 80, 18],
[17, 88, 95, 57, 67, 38, 12, 78, 21, 64],
[75, 41, 8, 72, 47, 77, 13, 98, 56, 71],
[96, 14, 50, 87, 24, 9, 48, 25, 11, 25],
[68, 16, 94, 30, 23, 41, 22, 96, 93, 33],
[10, 72, 84, 29, 59, 40, 86, 31, 82, 97],
[72, 33, 16, 78, 12, 6, 63, 25, 28, 24]])
A_ss = A - A.mean()/A.std()
A_ss
array([[15.48180308, 24.48180308, 38.48180308, 43.48180308, 96.48180308,
40.48180308, 75.48180308, 65.48180308, -0.51819692, 96.48180308],
[ 6.48180308, 50.48180308, 66.48180308, 0.48180308, 4.48180308,
87.48180308, 74.48180308, 42.48180308, 0.48180308, 2.48180308],
[28.48180308, 55.48180308, 7.48180308, 46.48180308, 55.48180308,
24.48180308, 69.48180308, 40.48180308, 47.48180308, -1.51819692],
[11.48180308, 16.48180308, 63.48180308, 79.48180308, 34.48180308,
0.48180308, 23.48180308, 5.48180308, 78.48180308, 16.48180308],
[15.48180308, 86.48180308, 93.48180308, 55.48180308, 65.48180308,
36.48180308, 10.48180308, 76.48180308, 19.48180308, 62.48180308],
[73.48180308, 39.48180308, 6.48180308, 70.48180308, 45.48180308,
75.48180308, 11.48180308, 96.48180308, 54.48180308, 69.48180308],
[94.48180308, 12.48180308, 48.48180308, 85.48180308, 22.48180308,
7.48180308, 46.48180308, 23.48180308, 9.48180308, 23.48180308],
[66.48180308, 14.48180308, 92.48180308, 28.48180308, 21.48180308,
39.48180308, 20.48180308, 94.48180308, 91.48180308, 31.48180308],
[ 8.48180308, 70.48180308, 82.48180308, 27.48180308, 57.48180308,
38.48180308, 84.48180308, 29.48180308, 80.48180308, 95.48180308],
[70.48180308, 31.48180308, 14.48180308, 76.48180308, 10.48180308,
4.48180308, 61.48180308, 23.48180308, 26.48180308, 22.48180308]])
from sklearn import preprocessing
A_scaled = preprocessing.StandardScaler().fit(A).transform(A)
A_scaled
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\utils\validation.py:595: DataConversionWarning: Data with input dtype int32 was converted to float64 by StandardScaler.
warnings.warn(msg, DataConversionWarning)
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\utils\validation.py:595: DataConversionWarning: Data with input dtype int32 was converted to float64 by StandardScaler.
warnings.warn(msg, DataConversionWarning)
array([[-0.74717972, -0.65678879, -0.40228321, -0.30436663, 2.05218778,
0.18323502, 1.00930339, 0.52228691, -1.25857909, 1.57983042],
[-1.03212114, 0.43088692, 0.47088965, -1.96104578, -1.37433265,
1.90564425, 0.97286644, -0.24284678, -1.22810502, -1.14002415],
[-0.33559767, 0.64005532, -1.3690103 , -0.18878437, 0.5251515 ,
-0.40311705, 0.79068171, -0.30938014, 0.20417627, -1.25576265],
[-0.87382035, -0.99145824, 0.37733541, 1.08262056, -0.25698903,
-1.28264517, -0.88541777, -1.47371401, 1.14887244, -0.73493943],
[-0.74717972, 1.93689944, 1.31287775, 0.15796243, 0.89759938,
0.036647 , -1.35909806, 0.88822041, -0.64909769, 0.59605324],
[ 1.08910942, -0.02928358, -1.40019504, 0.73587376, 0.15270363,
1.46588019, -1.32266112, 1.55355405, 0.41749476, 0.7985956 ],
[ 1.75397273, -1.15879297, -0.09043576, 1.31378509, -0.70392648,
-1.02611613, -0.04736803, -0.87491373, -0.95383839, -0.53239707],
[ 0.86748832, -1.07512561, 1.28169301, -0.88227796, -0.74117127,
0.14658802, -0.99472861, 1.48702068, 1.54503535, -0.30092008],
[-0.96880082, 1.26756054, 0.96984556, -0.92080539, 0.59964108,
0.10994101, 1.33723589, -0.67531364, 1.20982058, 1.5508958 ],
[ 0.99412895, -0.36395303, -1.15071708, 0.96703829, -1.15086393,
-1.13605715, 0.49918615, -0.87491373, -0.4357792 , -0.56133169]])
Baye's Theorem:
An important philosophy in Machine Learning and Statistics.
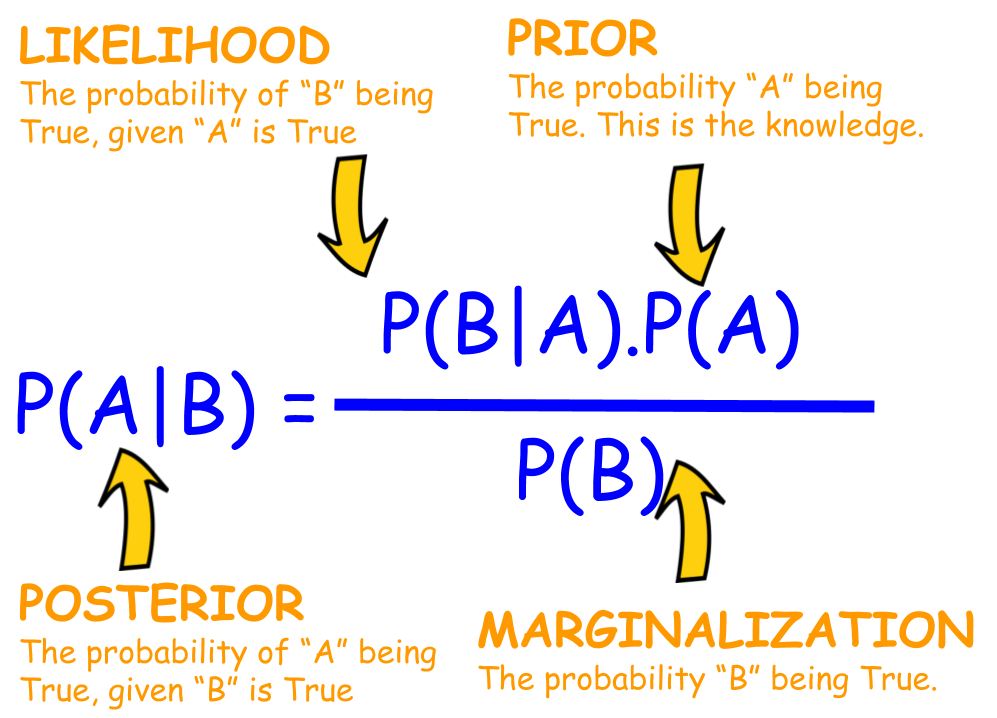
Important Topics: 1. Bayesian Classifier : Example of Machine Learning in Bayesian theory 2. Boltzman Machine: Example of Machine Learning for Physicist. 4. Quantum Boltzman Machine: Fusion of Machine Learning and Quantum Physics 5. Markove Random Field: Is there a Field Theory in Machine Learning?
A simple demo illustration Baye's theorm
A = (100*np.random.rand(10,4)).astype(int)
A
array([[38, 15, 66, 92],
[16, 60, 96, 18],
[18, 80, 14, 60],
[88, 41, 31, 33],
[88, 95, 24, 98],
[39, 64, 97, 76],
[17, 20, 1, 87],
[90, 34, 2, 70],
[81, 10, 93, 86],
[60, 56, 3, 63]])
df = pd.DataFrame(A, columns= ['bud','green','ripen','rotten'],\
index= ['apple','guava','mango','orange','banana','pear','papaya','strwberrey','grape','melon'])
df
| bud | green | ripen | rotten | |
|---|---|---|---|---|
| apple | 38 | 15 | 66 | 92 |
| guava | 16 | 60 | 96 | 18 |
| mango | 18 | 80 | 14 | 60 |
| orange | 88 | 41 | 31 | 33 |
| banana | 88 | 95 | 24 | 98 |
| pear | 39 | 64 | 97 | 76 |
| papaya | 17 | 20 | 1 | 87 |
| strwberrey | 90 | 34 | 2 | 70 |
| grape | 81 | 10 | 93 | 86 |
| melon | 60 | 56 | 3 | 63 |
df.sum()
bud 535
green 475
ripen 427
rotten 683
dtype: int64
sum(df.sum())
2120
df.loc['apple','bud']
38
df.loc['apple',:]
bud 38
green 15
ripen 66
rotten 92
Name: apple, dtype: int32
df.loc[:,'ripen']
apple 66
guava 96
mango 14
orange 31
banana 24
pear 97
papaya 1
strwberrey 2
grape 93
melon 3
Name: ripen, dtype: int32
- P(ripen|apple) = ?
df.loc['apple','ripen']/df.loc['apple',:].sum()
0.3127962085308057
- P(apple|ripen) = ?
df.loc['apple','ripen']/df.loc[:,'ripen'].sum()
0.15456674473067916
Implementing Baye's theorem
- $P(apple|ripen) = \frac{p(ripen|apple)*p(apple)}{p(ripen)}$
p_apple = df.loc['apple',:].sum()/sum(df.sum())
p_ripen_given_apple = df.loc['apple','ripen']/df.loc['apple',:].sum()
p_ripen = df.loc[:,'ripen'].sum()/sum(df.sum())
p_apple_given_ripen = (p_ripen_given_apple*p_apple)/p_ripen
p_apple_given_ripen
0.15456674473067916
Mini Assignment:
- Generate a randum array of size 10 by 10 and convert it to pandas dataframe with column name and row name of your interest
- Perform feature scaling (minimax scalar and standard scalar) by direct calculation of minimunm, maximum, mean, standard deviation from dataframe/array
- Implement Scikit-learn preprocessing pipeline to perform feature scaling